
Predictive vs. causal inference: a critical distinction
In the era of AI/ML, Machine Learning is often used as a hammer to solve every problem. While ML is profoundly useful and important, ML is not always the solution.
Most importantly, Machine Learning is made essentially for predictive inference, which is inherently different from causal inference. Predictive models are incredibly powerful tools, allowing us to detect patterns and associations, but they fall short in explaining why events occur. This is where causal inference steps in, allowing for more informed decision-making, that can effectively influence outcomes and go beyond mere association.
Predictive inference exploits correlations. So if you know that “Correlation does not imply causation”, you should understand that Machine Learning should not be used blindly to measure causal effects.
Mistaking predictive inference for causal inference can lead to costly mistakes as we are going to see together! To avoid making such mistakes, we will examine the main differences between these two approaches, discuss the limitations of using machine learning for causal estimation, explore how to choose the appropriate method correctly, how often they work together to solve different parts of a question, and explore how both can be effectively integrated within the framework of Causal Machine Learning.
This article will answer the following questions:
- What is causal inference and what is predictive inference?
- What are the main differences between them, and why does correlation not imply causation?
- Why is it problematic to use Machine Learning for inferring causal effects?
- When should each type of inference be used?
- How can causal and predictive inference be used together?
- What is Causal Machine Learning and how does it fit into this context?
What is predictive inference?
Machine Learning is about prediction.
Predictive inference involves estimating the value of something (an outcome) based on the values of other variables (as they are). If you look outside and people are wearing gloves and hats, it is most certainly cold.
Examples:
- Spam filter: ML algorithms are used to filter incoming emails between safe and spam using the content, the sender, and other various information attached to an email.
- Tumor detection: Machine Learning (Deep Learning) can be used to detect brain tumors from MRI images.
- Fraud detection: In banking, ML is used to detect potential fraud based on credit card activity.
Bias-variance: In predictive inference, you want a model able to predict the outcome well, most of the time out-of-sample (with new unseen data). You might accept a bit of bias if it results in lower variance in the predictions.
What is causal inference?
Causal inference is the study of cause and effect. It is about impact evaluation.
Causal inference aims to measure the value of the outcome when you change the value of something else. In causal inference, you want to know what would happen if you change the value of a variable (feature), everything else equal. This is completely different from predictive inference where you try to predict the value of the outcome for a different observed value of a feature.
Examples:
- Marketing campaign ROI: Causal inference helps to measure the impact (consequence) of a marketing campaign (cause).
- Political Economy: Causal inference is often used to measure the effect (consequence) of a policy (cause).
- Medical research: Causal inference is key to measuring the effect of drugs or behavior (causes) on health outcomes (consequence).
Bias-variance: In causal inference, you do not focus on the quality of the prediction with measures like R-square. Causal inference aims to measure an unbiased coefficient. It is possible to have a valid causal inference model with a relatively low predictive power as the causal effect might explain just a small part of the variance of the outcome.
Key conceptual difference: The complexity of causal inference lies in the fact that we want to measure something that we will never actually observe. To measure a causal effect, you need a reference point: the counterfactual. The counterfactual is the world without your treatment or intervention. The causal effect is measured by comparing the observed situation with this reference (the counterfactual).
Imagine that you have a headache. You take a pill and after a while, your headache is gone. But was it thanks to the pill? Was it because you drank tea or plenty of water? Or just because time went by? It is impossible to know which factor or combination of factors helped as all those effects are confounded. The only way to answer this question perfectly would be to have two parallel worlds. In one of the two worlds, you take the pill and in the other, you don’t. As the pill is the only difference between the two situations, it would allow you to claim that it was the cause. But obviously, we do not have parallel worlds to play with. In causal inference, we call this: The fundamental problem of causal inference.

So the whole idea of causal inference is to approach this impossible ideal parallel world situation by finding a good counterfactual. This is why the gold standard is randomized experiments. If you randomize the treatment allocation (pill vs. placebo) within a representative group, the only systematic difference (assuming that everything has been done correctly) is the treatment, and hence a statistically significant difference in outcome can be attributed to the treatment.
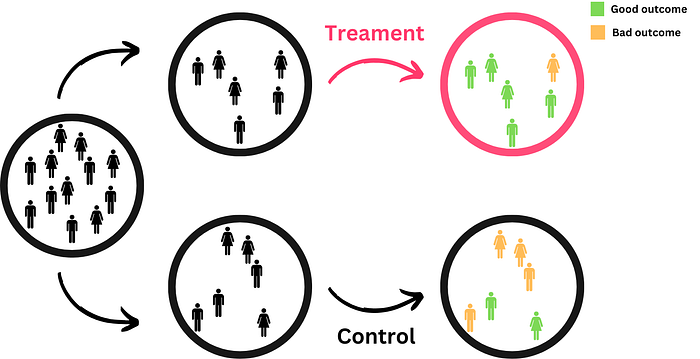
Note that randomized experiments have weaknesses and that it is also possible to measure causal effects with observational data. If you want to know more, I explain those concepts and causal inference more in-depth here:
Why does correlation not imply causation?
We all know that “Correlation does not imply causation”. But why?
There are two main scenarios. First, as illustrated below in Case 1, the positive relationship between drowning accidents and ice cream sales is arguably just due to a common cause: the weather. When it is sunny, both take place, but there is no direct causal link between drowning accidents and ice cream sales. This is what we call a spurious correlation. The second scenario is depicted in Case 2. There is a direct effect of education on performance, but cognitive capacity affects both. So, in this situation, the positive correlation between education and job performance is confounded with the effect of cognitive capacity.
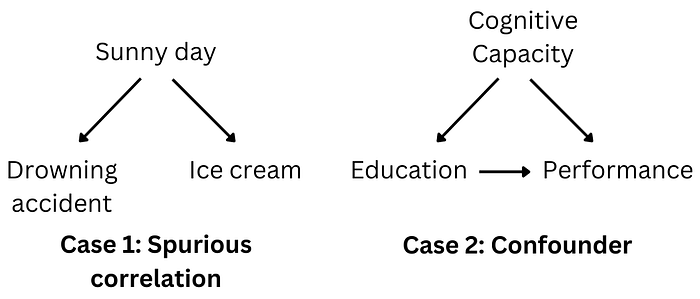
As I mentioned in the introduction, predictive inference exploits correlations. So anyone who knows that ‘Correlation does not imply causation’ should understand that Machine Learning is not inherently suited for causal inference. Ice cream sales might be a good predictor of the risk of drowning accidents the same day even if there is no causal link. This relationship is just correlational and driven by a common cause: the weather.
However, if you want to study the potential causal effect of ice cream sales on drowning accidents, you must take this third variable (weather) into account. Otherwise, your estimation of the causal link would be biased due to the famous Omitted Variable Bias. Once you include this third variable in your analysis you would most certainly find that the ice cream sales is not affecting drowning accidents anymore. Often, a simple way to address this is to include this variable in the model so that it is not ‘omitted’ anymore. However, confounders are often unobserved, and hence it is not possible to simply include them in the model. Causal inference has numerous ways to address this issue of unobserved confounders, but discussing these is beyond the scope of this article. If you want to learn more about causal inference, you can follow my guide, here:
Hence, a central difference between causal and predictive inference is the way you select the “features”.
In Machine Learning, you usually include features that might improve the prediction quality, and your algorithm can help to select the best features based on predictive power. However, in causal inference, some features should be included at all costs (confounders/common causes) even if the predictive power is low and the effect is not statistically significant. It is not the predictive power of the confounder that is the primary interest but rather how it affects the coefficient of the cause we are studying. Moreover, there are features that should not be included in the causal inference model, for example, mediators. A mediator represents an indirect causal pathway and controlling for such variables would prevent measuring the total causal effect of interest (see illustration below). Hence, the major difference lies in the fact that the inclusion or not of the feature in causal inference depends on the assumed causal relationship between variables.